

Most organizations do not wake up one morning and decide to overhaul how they manage messaging and streaming. The shift usually begins with something far less glamorous. A delayed release because a queue wasn’t provisioned on time. A compliance reviewer is asking for audit evidence that takes days to assemble. A capacity scare on a Kafka cluster that no one saw coming. Or the familiar moment in a war room when everyone realizes the issue is happening somewhere between five different platforms, and no one has the full picture.
These incidents are usually dismissed as “part of the job”. They sit quietly in the background, tolerated but not solved. Then they accumulate. And eventually the realization sets in: the organization is operating its most critical digital plumbing through a system of fragmented tools, tribal knowledge, spreadsheets, screenshots, and luck.
The good news is that there is a way out of this. A new operational model is emerging that allows large organizations to run their messaging and streaming estates with far more efficiency, resilience, and auditability than what has been possible before. But before we get there, we need to understand how the current model became so strained.
The Reality No One Talks About: Middleware Has Become Too Big To Manage Conventionally
If middleware were still a neat, single-platform world, most enterprises would not have a problem. But the world changed. Acquisitions happened. Digital programs layered new technologies on top of old ones. Critical systems stayed on MQ. Cloud teams adopted native messaging. Modern apps moved to Kafka. Integration teams added Solace. Microservices brought in RabbitMQ. Different business units made different choices at different times.
Now, most organizations operate a collection of platforms that were never designed to be viewed or run together.
This creates three immediate problems.
- Operational Fragmentation: Every platform has its own way of working. Kafka has partitions and consumer groups. MQ has channels and queues. Solace has VPNs and message spools. Cloud brokers follow their own patterns. Tools are inconsistent, naming
conventions drift, monitoring is disconnected, and incident diagnostics spread across too many places. The operational view becomes blurred. Teams spend time stitching context instead of solving problems. - An Unsustainable Human Workload: The people who understand this infrastructure are both scarce and overloaded. They are asked to provision objects manually, review ACLs, check configurations, investigate drift, run failovers, validate release plans, decode logs, triage incidents, and locate the source of message failures. Repetition becomes the norm. Heroics become the expectation. This is not a scalable operating model for a multi-platform estate.
- Blind Spots in Risk and Compliance: Most organizations can prove that “something happened,” but not necessarily “what happened,” “where it happened,” or “why it happened.” Regulators and audit teams want traceability, consistency, and evidence. Middleware estates rarely provide it.
A fragmented environment makes even basic audit questions difficult. Who changed this configuration? Which systems participated in this transaction? Was the failure internal or external? Did messages retry. Was the security model consistent? These questions require coordinated visibility, which is difficult when data is spread across incompatible logs and systems.
This gap is becoming more dangerous as regulations tighten around operational resilience.
The Hidden Costs: Waste, Delay, and Defensive Operations
The consequences of this operating model are often underestimated because they are dispersed across many teams.
- Infrastructure Waste
Most organizations cannot see true utilization across all messaging technologies. They over-provision Kafka storage. They leave unused queues and topics running for years. They maintain oversized clusters. They duplicate environments because it is easier than cleaning up. Storage, compute, and licensing bills grow gradually, rarely challenged because no one has a system-wide context. - Slow Delivery and Change Friction
Provisioning a new topic or queue should take minutes. In most enterprises, it becomes a mini-project involving approvals, compliance reviews, manual configuration, and cross-team coordination. Release cycles slow down not because of application development, but because of the plumbing beneath it. - Incident Resolution Drag
A business-critical slowdown might start in one platform and surface in another. Without visibility, teams chase symptoms. War rooms stretch into hours. Incidents that should be diagnosed quickly turn into cross-functional investigations. Mean Time to Recovery expands. Customer-facing systems suffer. - Compliance Overhead
Audit requests become painful exercises in log mining, screenshot gathering, Excel reconciliation, and interpretation. Evidence gathering interrupts real work. Compliance results take weeks. Reviewers lose confidence in the underlying controls. Findings start appearing in reports.
These costs accumulate quietly but powerfully.
A New Pressure Point: Auditability Has Become Strategic
A decade ago, auditability was mostly an internal concern. Today, it is a board-level conversation. Regulators across financial services, healthcare, energy, and the public sector now require organizations to prove the resilience and traceability of their operational systems.
Messaging and streaming platforms sit at the heart of these systems, but they remain some of the least auditable components in the digital landscape.
Why Auditability is so Hard Today
- No unified audit trail. Kafka, MQ, Solace, RabbitMQ, and cloud brokers all produce different artifacts. Correlating them manually is slow and error-prone.
- Configuration drift is constant. Even small changes create gaps in compliance evidence. Without unified configuration intelligence, drift remains invisible.
- RBAC inconsistencies multiply risk. Each platform has its own security model. Proving consistency across them is almost impossible manually.
- Incident reconstruction takes too long. When things go wrong, teams must recreate the past using logs from multiple systems, often with incomplete or misaligned timestamps.
- Compliance slows the business. Approvals take longer. Reviews take longer. Evidence takes longer. This becomes a tax on every change and every release.
Without built-in auditability, a middleware estate simply cannot operate at the speed the business requires.
The Shift: Lean Operations As A Strategic Imperative
Lean operations is not a slogan. It is not about doing more with less. It is the recognition that the old operating model cannot sustain the scale, complexity, and regulatory expectations of modern middleware estates.
A lean model has four defining characteristics.
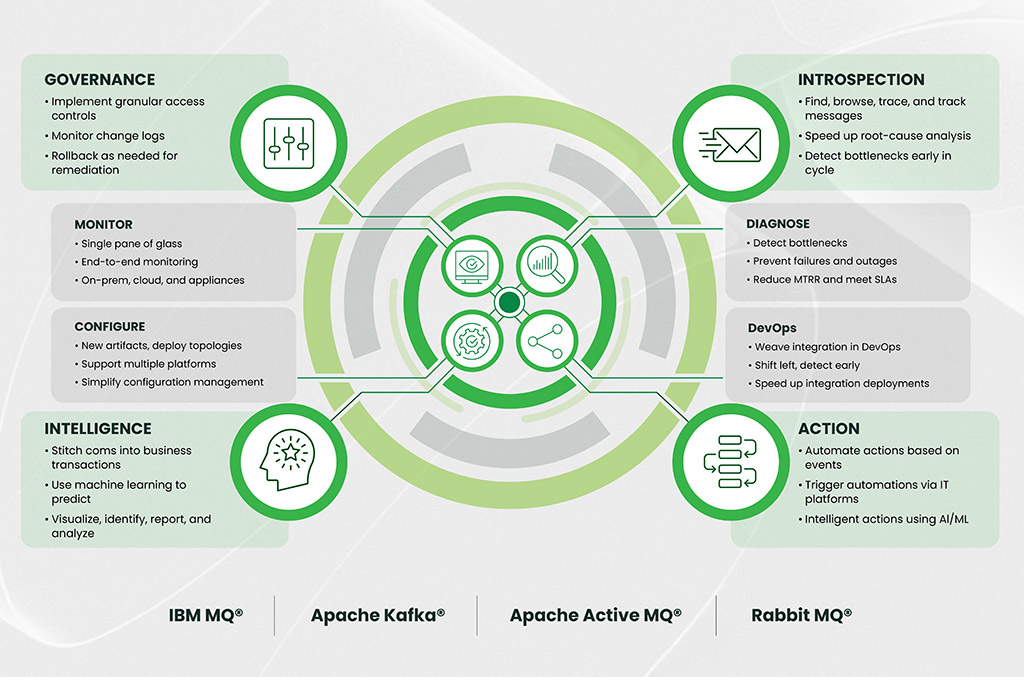
- Unified Visibility
Teams need to see the entire estate in one place: health, flows, dependencies, performance, lineage, configuration, and security. Not summaries. Not partial views. Actual end-to-end operational clarity. Without this, speed and reliability are impossible. - Automation and Controlled Self-Service
Provisioning, validation, drift detection, ACL checks, failover routines, and compliance evidence should not rely on manual effort. Automation removes friction. Policy-based self-service allows developers to work faster without increasing operational risk. - Resource Optimization
A lean model gives clear insight into what is oversized, under-utilized, misconfigured, or simply no longer needed. The result is lower infrastructure cost, more predictable capacity planning, and fewer performance surprises. - Built-in Auditability
Audit trails must be complete, consistent, and automatically captured. Configuration history must be reliable. Access models must be validated across platforms. Incident reconstruction must be fast. Evidence must be exportable without effort.
Lean operations is what happens when you combine these principles. It is not a tool. It is an operating philosophy supported by the right platform capabilities.
The Future State: Middleware As A Governed, Efficient, and Transparent Layer
Organizations that embrace this model experience a radically different operational reality.
Release cycles become smoother because provisioning and compliance do not hold them back. Outages become less frequent and shorter because teams can identify root causes quickly. Platform teams spend less time firefighting and more time improving. Infrastructure costs fall because utilization is visible and manageable. Audit requests that once took days are delivered in minutes. Regulators gain confidence in the organization’s operational discipline.
The biggest shift, however, is cultural. Developers stop waiting for middleware teams. Middleware teams stop playing catch-up. Compliance teams stop battling for evidence. Everyone operates with the same truth, the same visibility, and the same level of control.
This is the future state that progressive organizations are now moving toward.
So What Makes This Future State Possible?
Very few platforms are capable of supporting the operational model described here. Most observability tools focus on metrics rather than message flows. Most monitoring solutions are tied to a single platform. Integration tools typically manage connectivity, not operations. Open-source utilities provide valuable functions but lack governance, auditability, and cross-platform consistency. Cloud services help but introduce their own silos.
To reach a fully lean operating model, organizations need something that is still rare: a unified operational command plane that spans every messaging and streaming platform in the estate.
It must provide:
- A single operational view across all technologies
- Transaction-level lineage and flow analysis
- End-to-end audit trails
- Consistent configuration and security governance
- Automated provisioning and validation
- Self-service within guardrails
- Capacity and cost intelligence
- Multi-cloud and hybrid compatibility
- Integration with existing processes, not disruption of them
When these capabilities come together, the fragmented middleware world becomes manageable. It becomes transparent. And it becomes compliant.
This is the model that forward-thinking organizations are now adopting.
And this is exactly the model made possible by meshIQ Core.
meshIQ appears at the end of this story not because it is an afterthought, but because the logic leads naturally to it. Once you understand the operational, architectural, and compliance realities of modern messaging and streaming, the need for a unified control plane becomes obvious. meshIQ is one of the few platforms purpose-built to deliver it, and for many organizations, it has become the turning point from reactive, high-cost operations to a lean, governed, and resilient operating model.