

Published April 30, 2025
Why Enterprise Middleware Teams Need More Than Just Prometheus & Grafana


The Limitations of Prometheus & Grafana for Middleware Teams
Let’s be real, Prometheus and Grafana are great tools. They’ve earned their place in enterprise IT by offering solid infrastructure monitoring and visualization. But in complex, multi-middleware environments, these tools hit their limits.
Picture this: a business-critical transaction is delayed or missing. Dashboards look fine. CPU and memory are stable. But something still feels off. Teams start flipping between dashboards, querying metrics, and stitching together logs from Kafka, IBM MQ, and RabbitMQ. Hours go by, and the issue is still unresolved.
That’s because Prometheus and Grafana were built for infrastructure metrics. They don’t give you insight into what’s happening inside message queues, brokers, or event streams. They can detect certain anomalies when configured with the right rules, but they don’t deliver real-time, contextual awareness of how messages flow through middleware.
Understanding Message-Level Failures
Imagine a retailer operating multiple online storefronts during the busiest shopping day of the year. Orders are pouring in continuously, and systems appear to be handling the load without issue. But suddenly, the customer support lines light up. Customers report strange problems with their orders. Some received multiple order confirmations for a single purchase, while others have been charged twice but received only one confirmation email.
From an infrastructure perspective, everything looks fine. Prometheus indicates no spikes in CPU or memory usage, no alerts on queue depths, and no visible Kafka broker health issues. But something critical is clearly going wrong within the message processing flow itself.
Here’s the deeper issue: Tools like Prometheus excel at providing infrastructure metrics and alerting based on thresholds, but they lack visibility into the content and context of messages. They won’t alert you when messages are duplicated due to an application-level retry logic issue. They also won’t show when transactions diverge into inconsistent states or if message payloads become corrupted as they move through brokers and queues.
This leaves middleware teams digging manually through logs across Kafka, IBM MQ, RabbitMQ or other systems to trace down what went wrong. Hours may pass before the team can identify the source of duplication or inconsistency. Without end-to-end message tracking and correlation, troubleshooting becomes slow, expensive, and reactionary.
Middleware management requires visibility beyond basic metrics. Effective management means tracking individual messages, correlating them across systems, and providing real-time context to resolve problems rapidly before they impact customers.
Observability and Message Tracking Are Not the Same Thing
This is where the distinction matters. Observability shows you the health of systems. Message tracking shows you the flow of data through those systems. They are complementary, but not interchangeable.
A full view of middleware health requires both. You need to see how transactions move across queues, brokers, and service buses. You need to pinpoint where things slow down, and why. This means tracking message flows across multiple platforms, identifying latency and failure points, and aligning technical data with business outcomes.
Prometheus and Grafana answer questions like “Is the server under stress?” They do not answer “Did this transaction complete?” or “Why is this order still waiting in the queue?”

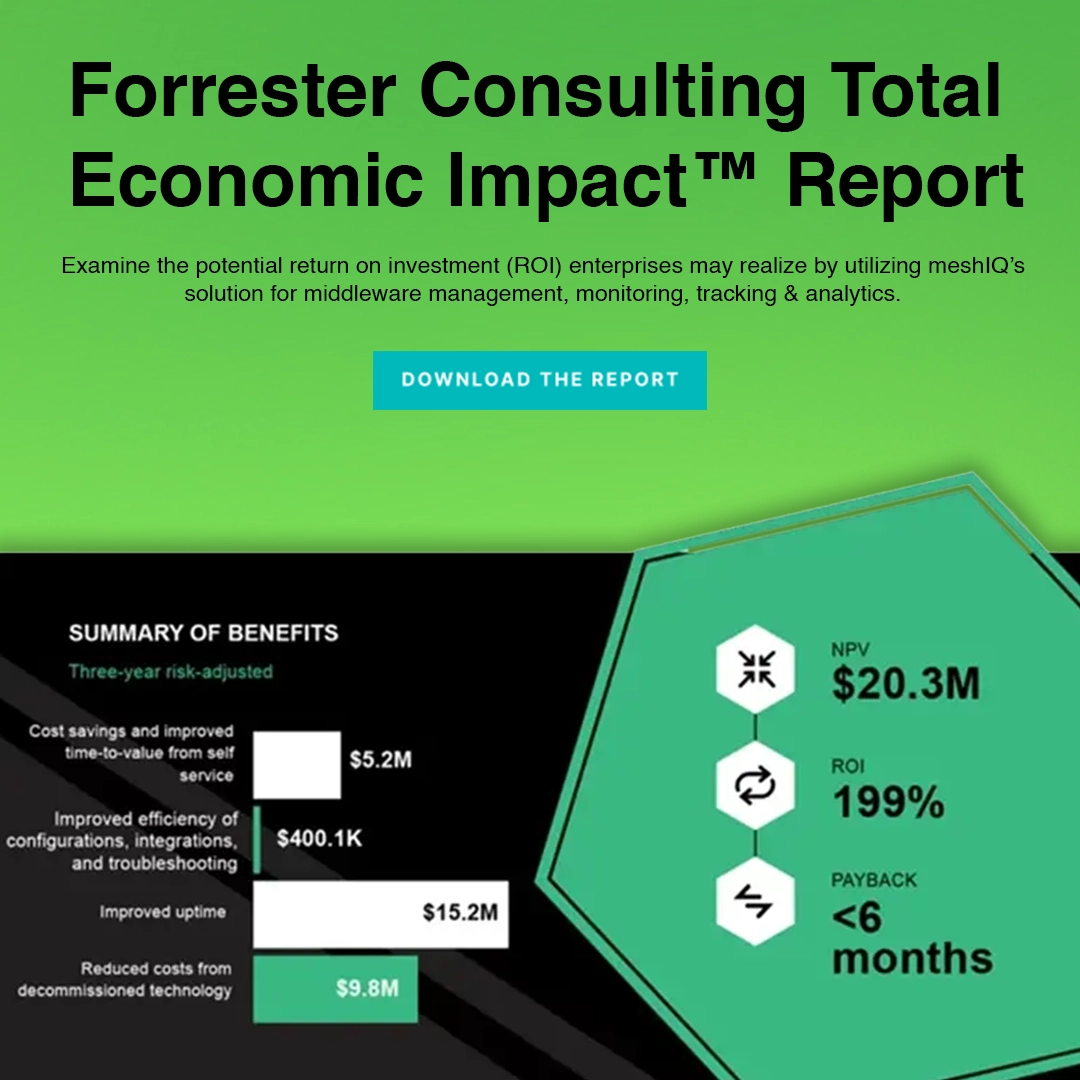
Why Proper Middleware Management Matters
Even with strong observability and message tracking, teams still need the ability to act on insights. Middleware is constantly evolving. Configuration drift, lack of role-based access, inconsistent topic management, and unplanned growth all contribute to performance issues.
Here’s what poor middleware management leads to:
- Untracked changes to queues, topics, or broker settings
- Security gaps from inconsistent access control
- Costly manual troubleshooting across distributed systems
- Delays in resolving issues even after detection
Middleware environments need to be managed, not just monitored. That means optimizing performance, enforcing governance, and proactively correcting issues before they cause user-facing problems.
How meshIQ Solves the Gap
meshIQ is purpose-built for this challenge. It combines observability, tracking, and middleware management into a unified platform. Unlike Prometheus and Grafana, meshIQ provides:
- End-to-end transaction tracking across hybrid environments
- Smart alerting for queue depth, message failures, and topic growth
- Kafka-specific operations like Smart Rebalance and lag detection
- Cross-platform visibility for IBM MQ, Kafka, Solace, RabbitMQ, and more
- Governance tools to manage configuration, access, and policy enforcement
With meshIQ, middleware teams stop reacting and start operating with control and confidence.
Looking Ahead
Middleware complexity is only increasing. As more businesses embrace hybrid cloud, real-time streaming, and event-driven architectures, the cracks in traditional monitoring will widen.
Prometheus and Grafana still have value, but they are no longer enough on their own. For true visibility and control, teams need to observe, manage, and track their entire middleware ecosystem. That’s where meshIQ comes in.
- Category:
- Middleware